Abstract
Large language model (LLM)-based text-to-speech (TTS) systems achieve remarkable naturalness via autoregressive (AR) decoding, but require N sequential steps to generate N speech tokens. We present LLaDA-TTS, which replaces the AR LLM with a masked diffusion model that completes generation in a fixed number of parallel steps, decoupling inference latency from sequence length. Using only 50 hours of fine-tuning data, we successfully transfer a pretrained AR checkpoint (CosyVoice 3) to the masked diffusion paradigm. At 64 steps, LLaDA-TTS achieves 0.98% CER (zh) and 1.96% WER (en) on Seed-TTS-Eval, matching the AR baseline while delivering a 2× LLM-stage speedup. Beyond acceleration, the bidirectional architecture naturally enables zero-shot speech editing — word-level insertion, deletion, and substitution — without any additional training.
Architecture
LLaDA-TTS replaces the causal attention mask in the LLM decoder with full bidirectional attention and trains with a masked diffusion objective. The text encoder, sequence format, and downstream flow matching vocoder remain identical to the AR baseline (CosyVoice 3).
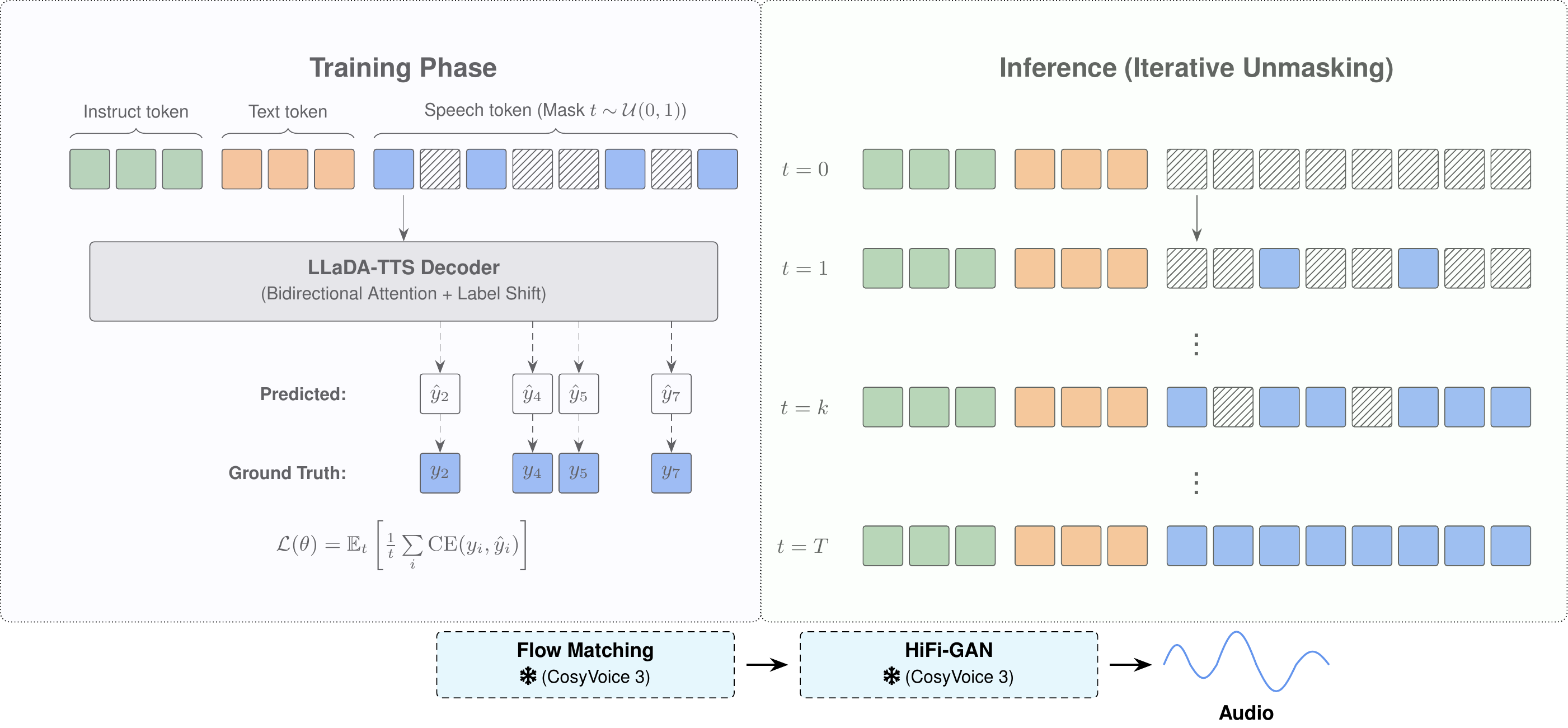
Figure 1: LLaDA-TTS architecture. A bidirectional Transformer (Qwen2-0.5B) iteratively unmasks speech tokens in T steps.
Zero-Shot In-Context Generation
Given a short prompt audio, LLaDA-TTS generates speech in the same voice for arbitrary text. We compare against the CosyVoice 3 AR baseline (same backbone, same vocoder — only the LLM decoder differs). All samples below are from the Seed-TTS-Eval benchmark.
Chinese
| Text | Prompt | AR Baseline (CosyVoice 3) | LLaDA-TTS (64 steps) |
|---|---|---|---|
| 共同建设面向未来的交通,和出行服务新生态。 | |||
| 女性可以成为成功的科学家,工程师和程序员。 | |||
| 通过调查,将筛选出一批口味令消费者满意的产品。 | |||
| 经济发展是城市高效宜居发展的基石。 | |||
| 互联网已经成为一种解决方案的应用层。 |
English
| Text | Prompt | AR Baseline (CosyVoice 3) | LLaDA-TTS (64 steps) |
|---|---|---|---|
| This pepperoni tastes off, she said. | |||
| Later, we simply let life proceed, in its own direction, toward its own fate. | |||
| I was well, but I'm all the better for being here. | |||
| The work of the tailor is seen on each side. | |||
| Also, will numbers be written as digits or as words? |
Speed–Quality Tradeoff
LLaDA-TTS allows controlling the quality–speed tradeoff by adjusting the number of denoising steps T. At 48 steps, it already surpasses the AR baseline CER (1.09% vs. 1.21%) with ~2.6× speedup.
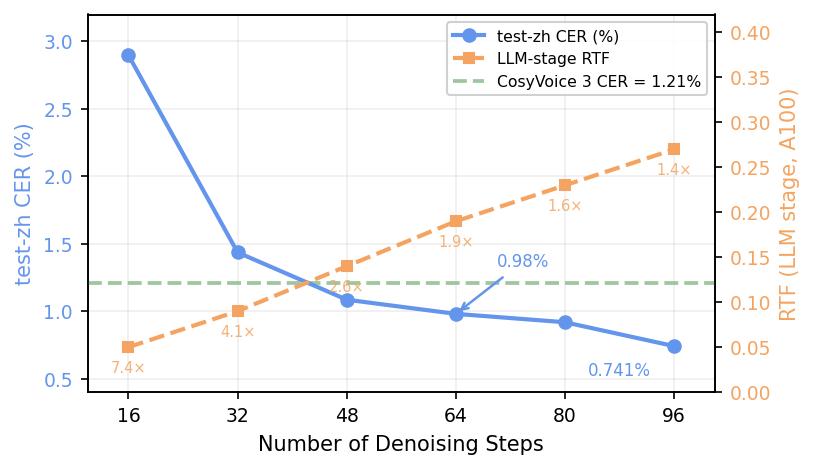
Figure 2: CER and RTF as a function of denoising steps. LLaDA-TTS surpasses the AR baseline at 48 steps.
Same Text, Different Steps
Chinese Text to Generate: "自动驾驶将大幅提升出行安全,效率。"
| Steps | CER (test-zh) | RTF (A100) | Audio |
|---|---|---|---|
| 16 steps | 2.90% | 0.05 | |
| 32 steps | 1.44% | 0.09 | |
| 48 steps | 1.09% | 0.14 | |
| 64 steps ⭐ | 0.98% | 0.19 | |
| 80 steps | 0.86% | 0.23 | |
| 96 steps | 0.74% | 0.27 |
English Text to Generate: "When it comes to the crunch, our company will become insolvent."
| Steps | Audio |
|---|---|
| 16 steps | |
| 32 steps | |
| 48 steps | |
| 64 steps ⭐ | |
| 80 steps | |
| 96 steps |
Zero-Shot Speech Editing
The bidirectional architecture naturally enables speech editing — given existing speech and a text edit, we mask the affected region and regenerate via iterative unmasking. No additional training required. Supports three edit operations: substitution, insertion, and deletion.
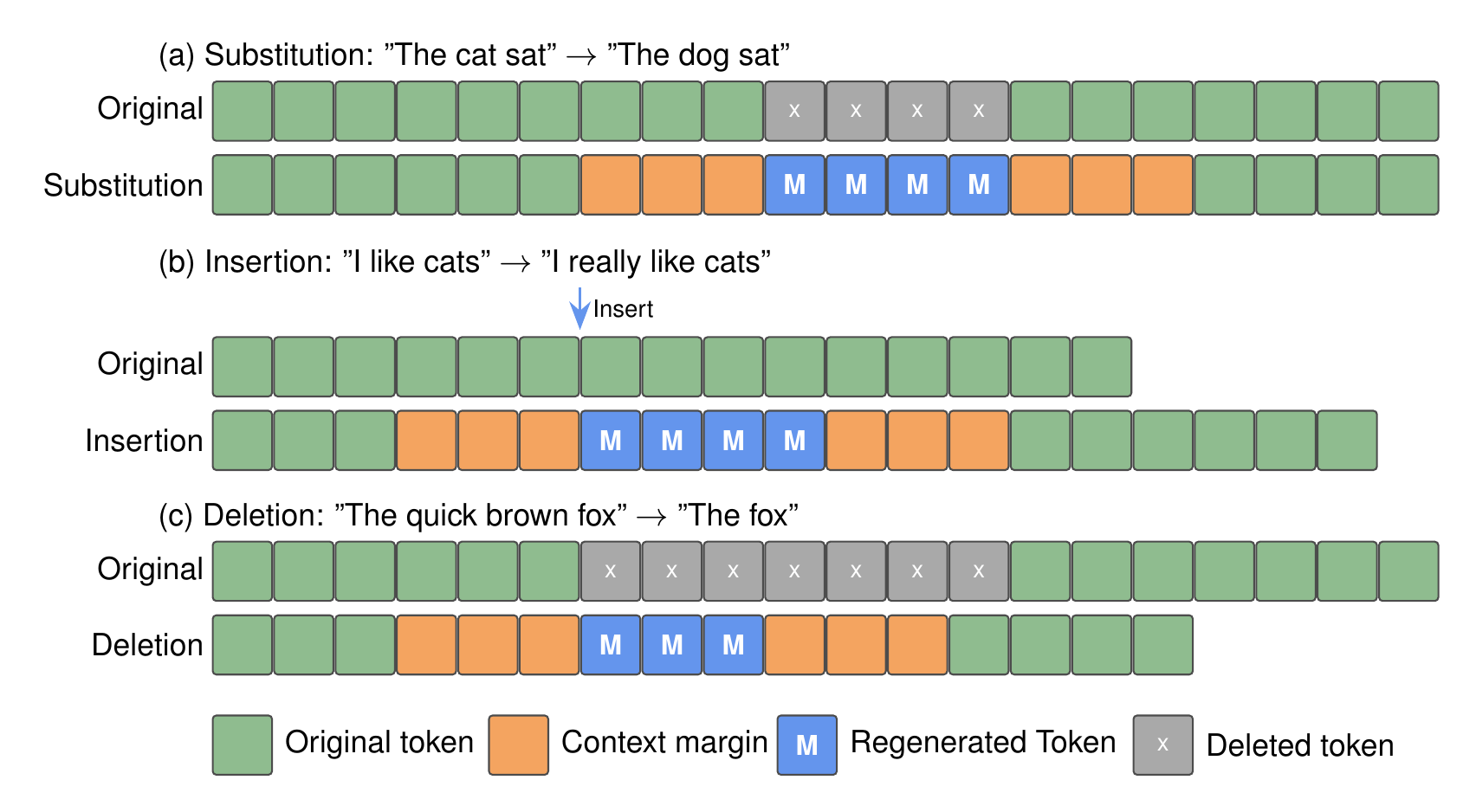
Figure 3: Speech editing pipeline. Text–speech alignment is extracted from cross-attention, the edit region is masked, and bidirectional context drives regeneration.
Chinese
| Operation | Edited Text | Audio |
|---|---|---|
| Substitution | 两辆大货车分别从奥迪奔驰车的后方和右方岔路口行进。 | |
| Insertion | 两辆大货车分别从飞驰的奥迪车的后方和右方岔路口行进。 | |
| Deletion | 两辆大货车分别从奥迪车的后方和右方岔路口行进。 |
English
| Operation | Edited Text | Audio |
|---|---|---|
| Substitution | This is a picture of a man woman cleaning off a diving board with a broom. | |
| Insertion | This is a picture of a tall man cleaning off a diving board with a broom. | |
| Deletion | This is a picture of a man cleaning off a diving board with a broom. |
Emergent Unmasking Behavior
Despite fully bidirectional attention, LLaDA-TTS exhibits a predominantly left-to-right unmasking order — sequential priors from AR pretraining persist in the diffusion regime, with confidence-based deviations that exploit bidirectional context.
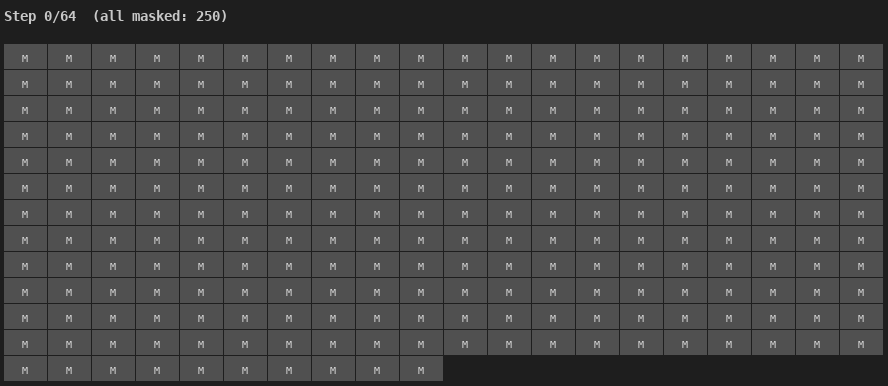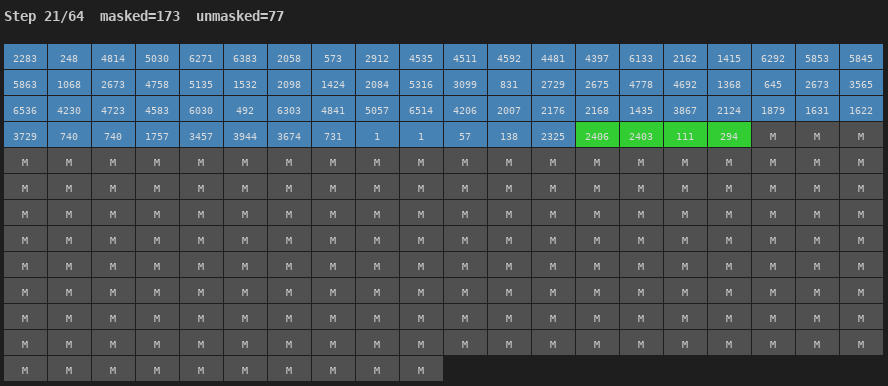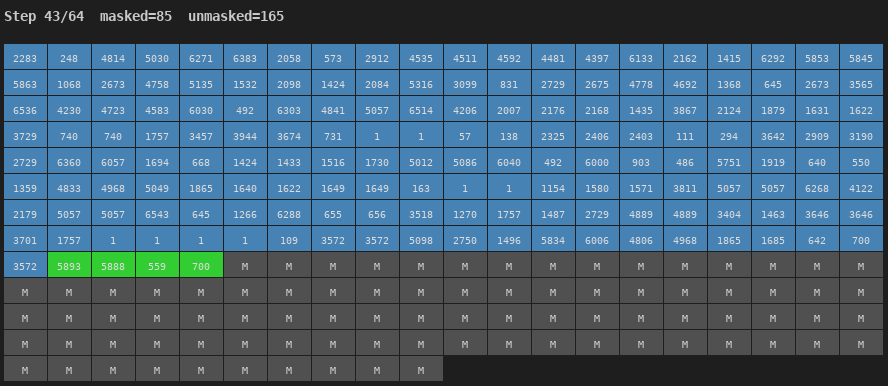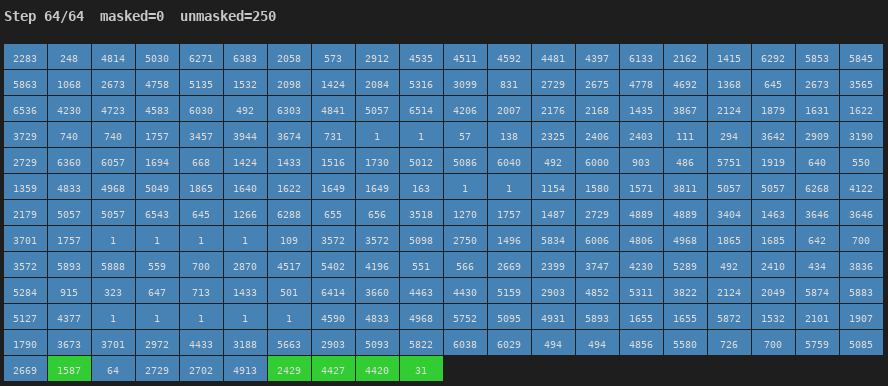
Figure 4: Unmasking process for a Chinese utterance (64 steps). Blue = early unmasking, Red = late. The generation sweeps predominantly left-to-right.
Benchmark Results
Evaluation on Seed-TTS-Eval (open-source leaderboard).
| Model | Type | test-zh CER↓ | test-en WER↓ | test-zh-hard CER↓ | SS↑ |
|---|---|---|---|---|---|
| Human | — | 1.26 | 2.14 | — | 75.5 |
| Seed-TTS | AR | 1.12 | 2.25 | 7.59 | 79.6 |
| VoxCPM | AR | 0.93 | 1.85 | 8.87 | 77.2 |
| MaskGCT | NAR | 2.27 | 2.62 | 10.27 | 77.4 |
| CosyVoice 3 | AR | 1.21 | 2.24 | 6.71 | 78.0 |
| LLaDA-TTS (64 steps) | Diffusion | 0.98 | 1.96 | 7.04 | 74.6 |